
微服务与服务拆分:何时拆、怎么拆
微服务与服务拆分:何时拆、怎么拆
微服务这几年火得不行,几乎成了"先进架构"的代名词。但真正难的从来不是"会不会用微服务框架",而是两个更朴素的问题:到底要不要拆?该怎么拆? 这两个问题答错了,你不会得到一套优雅的微服务,而是得到一个**"分布式单体"**——拆是拆开了,但服务之间藕断丝连,改一个要连带动三个,部署还得排着队上线,比原来的单体更难维护。
这是《服务端架构设计》系列的第七篇。承接《架构演进》篇里的痛点 4:单体代码膨胀、改不动、一处挂全挂、团队互相踩脚——这才是上微服务的真正理由。这一篇我们把"何时拆、怎么拆"摊开讲清楚:微服务到底是什么、为什么拆(以及为什么别急着拆)、按什么边界拆、业界用什么框架和方法论,以及那些拆完才发现的坑。
一、是什么:微服务就是按业务边界拆开的一堆小服务
是什么。 微服务(Microservices)是一种架构风格:把一个原本打包在一起的大应用,按业务边界拆成若干个可以独立开发、独立部署、独立扩容的小服务,每个服务管自己的一摊事、通常还管自己的一份数据,服务之间通过网络调用(HTTP / RPC)协作。对照《架构演进》篇里的单体——所有功能挤在一个进程、一个部署单元里——微服务就是把这个"大盒子"沿着业务的接缝劈成了好几个"小盒子"。
拆开之后,几件事会同时变化。 原来用户、订单、支付都在一个代码库里,现在变成三个独立的服务、三个独立的代码库、三个独立的发布流程。订单服务想加个功能,自己改、自己测、自己上线,不用再约着别的模块一起发版;支付服务流量大,就单独给它多加几台机器,而不用把整个应用一起扩容。"独立"是微服务的灵魂——独立开发、独立部署、独立扩容、独立故障隔离。
这里要点破一个常见的误解:微服务不等于"服务很多"或"服务很小"。 "micro"这个词容易让人以为越小越好,其实它强调的是单一职责和边界清晰,而不是物理上的代码行数。一个管着完整"订单"业务的服务,哪怕内部有几万行代码,也完全可以是一个合格的微服务;反过来,把一个本该内聚的业务硬切成十几个"贫血"的小服务,才是真正的灾难。
和它容易混的两个概念,顺手厘清。 一个是 SOA(面向服务的架构):微服务可以看作 SOA 思想的一种更轻量、更彻底的演化,去掉了 SOA 时代那个重型的 ESB(企业服务总线),让服务直接、点对点地协作。另一个是单体内部的模块化:单体里也可以分模块、分包,但它们最终还是编译进同一个进程、一起部署——模块化是逻辑上的拆,微服务是物理上的拆,后者才带来"独立部署"这个关键能力(以及随之而来的全部复杂度)。
所以一句话定位: 微服务是用**"物理上拆开、各自独立"的代价**,去换**"团队能并行、模块能解耦、局部能单独扩"的好处**——它不是更高级的单体,而是一组完全不同的权衡。
二、为什么拆,以及为什么别急着拆
为什么。 拆微服务的真正理由,从来不是"微服务更先进",而是单体长到一定体量后,协作、部署、稳定性这三笔成本同时扛不住了。这正好接上《架构演进》篇的痛点 4,把它说具体些:协作成本——几十个人挤在一个代码库里,合并冲突天天有,谁都不敢大改;部署成本——改一行字段也要把整个应用重新发一遍,发布越来越慢、越来越提心吊胆;稳定性成本——所有功能共用一个进程,某个边角模块内存泄漏或死循环,能把整个系统一起拖垮,故障无法隔离。当这三笔成本明显高于"拆开后多出来的分布式复杂度"时,拆才划算。
还有一类很实在的理由:技术栈和扩容粒度被绑死了。 单体里所有功能必须用同一套语言、同一套框架、同一个数据库,想给某个模块换个更合适的技术很难。而且扩容只能"整体扩"——明明只是支付这一块在大促时压力大,却得把整个应用连同那些没什么流量的模块一起复制好几份,既浪费机器又不解决问题。微服务让你能按服务选技术、按服务扩容,把资源花在真正吃紧的地方。
但更重要的,是反过来想:为什么别急着拆。 业界这些年一个越来越清醒的共识是 "单体优先"(Monolith First,Martin Fowler 提出):绝大多数项目应该从单体起步,等业务跑通、边界清晰、确实被痛点推着走了,再考虑拆分。原因很现实——创业初期你根本不知道业务的边界在哪。今天觉得"用户"和"账户"是两回事,过俩月发现它们的逻辑缠在一起;此时若已经拆成两个服务,改个边界就成了跨服务的大手术。单体内部调整边界几乎零成本,跨服务调整边界则代价高昂。
没到那个体量,单体是真的香。 一个日活几百、团队就三五个人的产品,一上来就拆十几个微服务,等于凭空给自己背上一整套分布式的复杂度:服务怎么互相发现、调用失败怎么重试、数据散在各服务里怎么对账、出了问题要顺着调用链翻好几个服务的日志……这些苦,你的流量根本不需要你去吃。微服务解决的是"大"带来的问题,而你还没"大"——这就是《架构演进》开篇说的过度设计,用大炮打蚊子。所以判断"该不该拆"的标准很朴素:不是"我们想不想更先进",而是"单体现在是不是真的疼了"。
三、怎么拆:按业务边界,而不是按技术分层
怎么拆是整篇里最考功夫的一环,核心就一句话:按业务能力拆,别按技术分层拆。 一个经典的错误是按"前端层 / 业务逻辑层 / 数据访问层"横切,拆出"控制器服务""逻辑服务""DAO 服务"——这样拆出来的服务谁也离不开谁,一个简单的下单要横穿三个服务,等于把一次本地函数调用变成了三次网络调用,只增加了延迟和故障点,没换来任何独立性。正确的切法是纵向的、按业务能力(Business Capability)切:用户、商品、订单、支付、库存,每个服务垂直地包含自己从接口到数据的一整条逻辑。
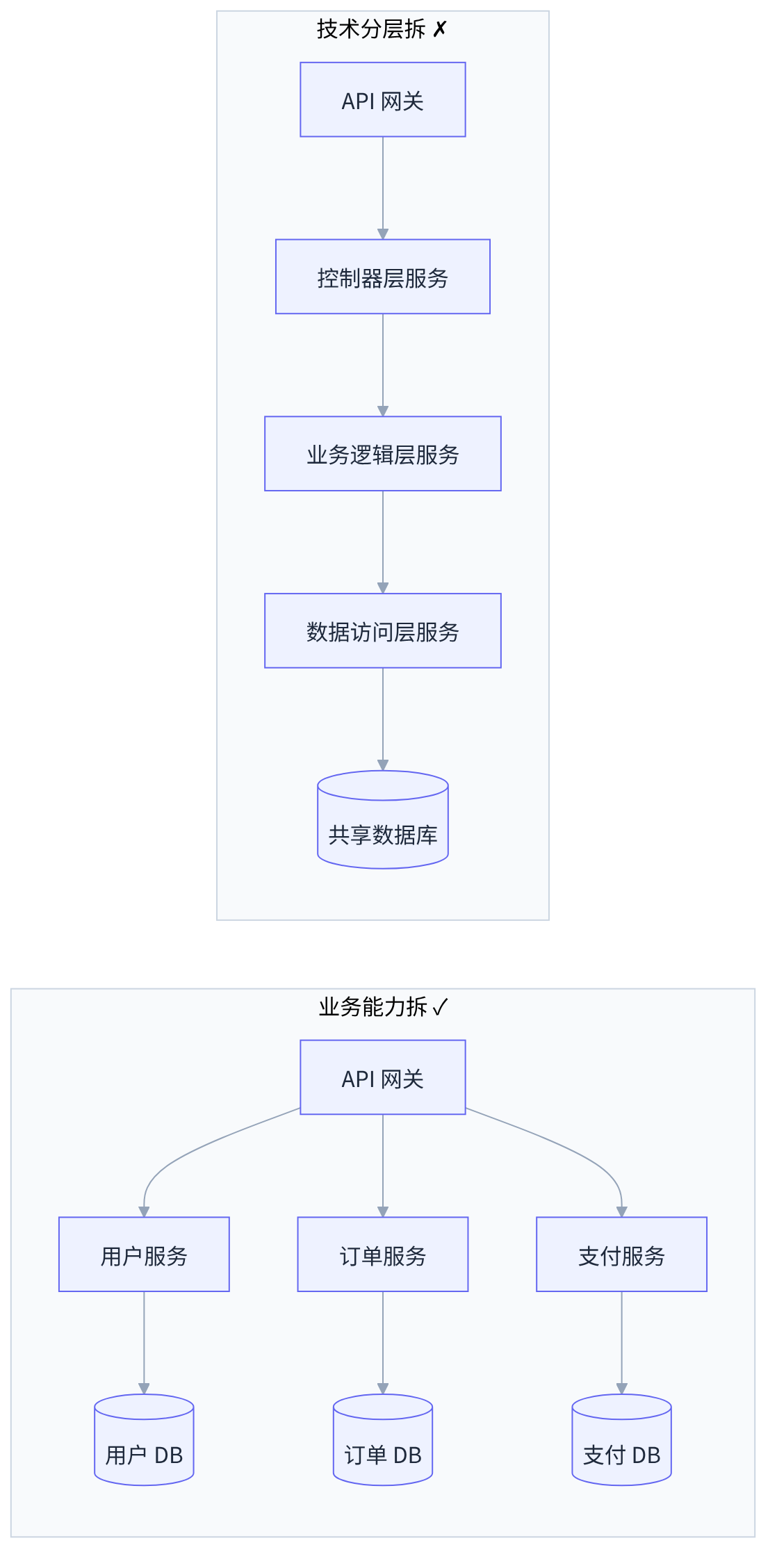
这套"按业务边界切"的方法,业界有一个成熟的理论支撑,就是 DDD(领域驱动设计)里的"限界上下文"(Bounded Context)。 限界上下文说的是:同一个词,在不同业务语境里其实是不同的东西——"商品"在商品中心是"标题、图片、参数、类目",在订单里只是"一个商品 ID 加下单时的快照价",在库存里则是"一个可扣减的数量"。每一个这样自成一体、有清晰语义边界的业务范围,就是一个天然的服务边界。 用一个具体的电商场景串起来就很直观:
| 候选服务 | 它负责的业务能力(限界上下文) | 大致不该管的事 |
|---|---|---|
| 用户服务 | 注册、登录、账号信息、实名 | 不管订单、不管钱 |
| 商品服务 | 商品信息、类目、上下架 | 不管库存数量、不管下单 |
| 订单服务 | 下单、订单状态流转、订单查询 | 不存商品详情,只存快照 |
| 支付服务 | 收银、支付渠道、对账 | 不管订单业务规则 |
| 库存服务 | 库存扣减、回滚、预占 | 不管商品的展示信息 |
粒度怎么把握,是这里最容易翻车的地方。 一个好用的判断标准是看内聚与耦合:经常一起改、强相关的东西,放进同一个服务(高内聚);很少互相影响、能独立演进的,才拆开(低耦合)。 如果你发现两个服务"几乎每次需求都要一起改、一起发版",那它们大概率就该是一个服务——这是个明确的"拆过头了"的信号。另一个朴素的参照是团队:一个服务最好能由一个小团队完整负责(端到端),不需要跨好几个团队协调才能改动它。
还有一个常被忽略的维度:数据。 划服务边界时,不光要看"这块业务逻辑归谁",还要看"这块数据归谁"。理想状态下,一份数据应该有唯一的"主人"服务,别的服务想要这份数据,通过调它的接口拿,而不是直接连它的库。如果你怎么切都切不干净——总有几张表被两个服务同时读写,那往往说明边界还没找对,得回到限界上下文重新审视,而不是急着把表也切开。边界找对了,数据归属自然清晰;数据老是扯不清,通常是边界本身画错了。
四、业界怎么做的
方法论层面,DDD(领域驱动设计)是绕不开的那一套。 它由 Eric Evans 在《领域驱动设计》一书里系统提出,核心就是前面用到的限界上下文、聚合、统一语言那一组概念——帮你在拆服务之前,先把业务的边界在"领域"层面想清楚。需要客观说明的是:DDD 是一套思考工具,不是银弹,它本身有上手门槛,小项目硬套全套 DDD 反而是负担;但"按业务边界而非技术分层来划分"这个核心思想,是被广泛认可的拆分指导原则。
框架层面,不同语言生态各有主流选择(以下都是客观罗列,不是推荐):
| 生态 | 代表框架 / 方案 | 大致定位 |
|---|---|---|
| Java | Spring Cloud | 微服务全家桶,注册发现、配置、网关、熔断一整套 |
| Java | Dubbo | 高性能 RPC 框架起家,侧重服务间调用与治理 |
| Go | Kratos、Go-Zero | Go 生态较流行的微服务框架,自带工程规范与代码生成 |
| 跨语言 | gRPC | Google 开源的通用 RPC 框架,常作为服务间通信底座 |
| 跨语言 | Spring Cloud Gateway / Kong / APISIX | API 网关,作统一入口(见《架构演进》篇) |
这些框架解决的主要是**"拆开之后怎么治理"**——服务怎么互相找到(注册发现:Nacos / Consul / etcd)、调用失败怎么办(熔断、重试、限流)、配置怎么统一管(配置中心:Nacos / Apollo)。注意:框架只解决"治理"问题,不解决"怎么拆"问题。 边界划不对,再好的框架也救不回来——这也是为什么 DDD 这类方法论和框架是两件事,缺一不可。
有一条规律值得单独点破,就是康威定律(Conway's Law): "设计系统的组织,其产出的系统结构会复刻该组织的沟通结构。" 翻译成大白话——你的团队怎么划分,服务边界往往就会长成那个样子。 三个团队做一个系统,大概率会拆出三个服务;反过来,如果你设计的服务边界跟团队的协作边界拧着来,落地时一定会很别扭。所以业界有个"逆康威操作"(Inverse Conway Maneuver)的说法:想要什么样的架构,就先把团队按那个样子组织起来。 拆服务这件事,本质上绕不开"团队怎么协作"。
最后给一个客观的行业背景:微服务不是终点,业界也在持续修正它。 一方面有"单体优先"的回潮(见第二节),另一方面这些年也出现了"模块化单体"(Modular Monolith)这样的折中思路——在单体内部用清晰的模块边界做好隔离,既享受单体的部署简单,又为将来真要拆时留好接缝。这些都说明:微服务是一个被广泛采用、但也被持续反思的方案,不是非黑即白的"先进 / 落后"。
五、注意事项(那些拆完才发现的坑)
第一个,也是最经典的坑:拆太细,拆出"分布式单体"。 这是开篇就提到的反面终局——服务拆了几十个,但彼此强耦合、必须一起改一起发版,等于把单体的"牵一发动全身"原封不动地搬到了网络上,还额外赔进去网络延迟和故障点。更隐蔽的后果是调用链爆炸:一个简单请求要串起七八个服务,其中任何一个慢了或挂了,整条链路跟着遭殊。判断信号很明确:如果服务之间总是同生共死,那就是拆过头了,该合并就合并。宁可先拆成几个"大一点"的服务,也别一上来切成一地碎片。
第二个坑:数据怎么拆。 这是微服务里最硬的一块骨头。原则上每个服务独立一个库(Database per Service),数据归属清晰、服务才能真正独立演进;但代价是——原来一条 SQL 的 JOIN 就能查出来的东西,现在得跨服务调接口拼数据。如果图省事让多个服务共享一个库(Shared Database),表面上方便了,实则又把服务通过数据库重新焊死:一个服务改个表结构,可能悄悄搞崩另一个服务,"独立部署"又成了空话。独立库是方向,但要做好"跨服务查询变麻烦"的心理准备——这笔代价省不掉,只能选择在哪付。
第三个坑:分布式复杂度是"打包附赠"的,躲不掉。 单体里,一次下单扣库存、记订单、发消息,可以放在一个本地数据库事务里,要么全成、要么全败。拆成微服务后,这变成了一个跨服务的分布式事务问题——订单服务成功了、库存服务却失败了,怎么保证最终一致?这是个出了名难的问题(本系列后面《分布式事务》篇会专门讲)。同理,服务多了之后的调用治理(超时、重试、熔断、限流、链路追踪)也都是新冒出来的功课。这句话值得记牢:拆微服务不是把复杂度消灭了,而是把"代码内部的复杂度"换成了"系统之间的复杂度",后者更难排查。
第四个坑:运维与排查成本陡增。 单体时代查 bug,翻一个日志文件就行;微服务时代,一个请求穿过五六个服务,你得把这几个服务的日志按调用链拼起来才看得明白——这正是《架构演进》痛点 5 的由来,也是为什么微服务几乎必须配套链路追踪、统一日志、监控告警这一整套可观测设施(留给本系列《可观测性》篇)。没有这套设施就贸然上微服务,等于摸黑开车。
最后,把"什么情况下不该拆"明确列出来,这和"怎么拆"同样重要: 业务还在快速变、边界没稳定下来时不该拆(拆了等着返工);团队人手少、撑不起多套服务的运维时不该拆;单体目前跑得好好的、没有明确痛点时不该拆。一句话总结这一整篇的态度:微服务是被痛点逼出来的解法,不是用来追的潮流。 该不该拆,永远先问"现在是不是真疼了",而不是"别人是不是都在拆"。
六、AI 系统的微服务拆法
AI 应用其实天然走微服务思路——只是边界有它自己的特点。一个典型的 LLM 产品后端,通常会有这几条清晰的服务边界:
- LLM 推理服务(或调用层):不管业务,只负责把 prompt 发给大模型、拿回回答;可以是对 OpenAI 这类 API 的封装,也可以是自托管的推理节点。这是 GPU 算力最密集的地方,天然独立部署、单独扩容。
- 向量检索服务:负责文档 embedding、入库和相似度搜索(RAG 场景),通常封在自己的服务里,对外只暴露"给我一段文本,返回最相关的 TopK 段落"。
- 业务服务:管用户、会话、历史记录、权限、计费——跟普通 Web 服务没本质区别,只是会调上面两个 AI 专属服务。
一个典型的反面案例:把 LLM 调用直接写进订单服务或用户服务里——看起来省事,但这样 GPU 资源、模型版本、token 限速这些事就分散在各处,改一个 prompt 或换个模型要动好几个服务。按业务能力拆分的原则在这里同样适用:LLM 调用是一个独立的"能力",就应该独立成一个服务(或至少一个 SDK 层),而不是散落在各个业务模块里。
还有一个 AI 特有的坑:模型版本和业务逻辑的边界。同一个 LLM 服务可能同时跑 GPT-4o 和 GPT-4o-mini 两个版本,不同业务场景按成本和质量诉求选不同版本——这是"LLM 服务内部的路由问题",不应该把版本选择逻辑泄漏到业务服务里。换句话说,业务服务只需要说"我要生成一段摘要",选哪个模型、怎么重试、怎么限速,都是 LLM 服务层的事,这才是边界清晰的拆法。
七、一张表:单体 vs 微服务
把全文收进一张对照表——注意最右边那两列没有绝对的优劣,只有"适合哪个业务阶段":
| 维度 | 单体(Monolith) | 微服务(Microservices) |
|---|---|---|
| 开发 | 一个代码库,上手快;但人多了易冲突 | 各服务独立开发,团队能并行;但需协调接口 |
| 部署 | 一次部署整个应用,简单 | 各服务独立部署、独立发版;但部署单元变多 |
| 扩容 | 只能整体扩,粒度粗、浪费资源 | 按服务精准扩容,资源花在刀刃上 |
| 故障隔离 | 一处挂可能全挂 | 单服务故障可隔离(前提:边界拆对) |
| 技术栈 | 全局统一,换技术难 | 可按服务选型,更灵活 |
| 数据 | 一个库,JOIN 方便、事务简单 | 倾向独立库,跨服务查询 / 事务变难 |
| 复杂度 | 低,排查直接 | 高,分布式复杂度 + 运维成本陡增 |
| 适合阶段 | 起步期、中小体量、边界未稳 | 大体量、多团队、单体已被痛点拖垮 |
名词解释
- 微服务(Microservices):把大应用按业务边界拆成若干可独立开发、部署、扩容的小服务,服务间经网络(HTTP / RPC)协作。强调单一职责和边界清晰,不等于"服务越多越小越好"。
- 单体(Monolith):所有功能打包在一个进程 / 一个部署单元里的应用。开发部署简单,但体量大了会面临协作、部署、故障隔离的瓶颈。
- SOA(面向服务的架构):比微服务更早的"按服务拆分"思想,常带重型的 ESB(企业服务总线);微服务可看作其更轻量、点对点的演化。
- 限界上下文(Bounded Context):DDD 里的核心概念——同一个词在不同业务语境下语义不同,每个自成一体、语义边界清晰的业务范围,就是一个天然的服务边界。
- DDD(领域驱动设计,Domain-Driven Design):Eric Evans 提出的一套以"领域 / 业务边界"为中心的设计方法论,是划分服务边界的主流指导思想(是思考工具,非银弹)。
- 服务边界:一个服务该管什么、不该管什么的分界线;划分原则是高内聚低耦合——常一起改的放一起,能独立演进的才拆开。
- 业务能力(Business Capability):按"业务做什么"来纵向划分服务(用户 / 商品 / 订单),对应"按技术分层横切"的错误切法。
- 康威定律(Conway's Law):系统结构倾向于复刻组织的沟通结构——团队怎么分,服务往往就怎么拆;反向利用即"逆康威操作"。
- 分布式单体(Distributed Monolith):拆成了多个服务、但彼此强耦合必须一起改一起发版的失败终局,比单体更难维护——拆分最该避免的反面案例。
- 单体优先(Monolith First):Martin Fowler 提出的实践建议——多数项目应从单体起步,业务和边界稳定、确被痛点推动后再拆微服务。
- 模块化单体(Modular Monolith):在单体内部用清晰模块边界做隔离的折中方案,兼顾部署简单与未来可拆性。
- Database per Service / 共享库:微服务的两种数据策略——前者每服务独立库(独立性强、跨服务查询难),后者多服务共享一库(方便但会把服务重新焊死)。
本文属《研发都要懂的事》·服务端架构设计系列,承接《架构演进》篇的痛点 4(单体膨胀、改不动、一处挂全挂)。拆完之后冒出的新痛点——分布式事务、调用治理、可观测——正是本系列后面几篇要逐一搞懂的主题。
评论(0)
登录后参与评论。
还没有评论,来抢沙发吧。
